The manuscripts are taken from the DocExplore project with the permission from the Municipal Library of Rouen, France. All manuscripts are dated back from 10th to 16th century. Each page has been scanned using the same setting with high resolution (600 dpi) resulting in images of the manuscript of a dimension ranging from 3000 pixels to 4000 pixels. For storage and computational issues, images are rescaled to a maximum size of 1024 pixels on each dimension and thus stored in low-resolution format (72 dpi) with 90% JPEG compression quality. Below are some images extracted from the manuscripts:

Example of image in DocExplore dataset.
After close work with historians in the field of medieval studies, we have defined a set of interesting objects for historians, divided into 35 categories of objects, ranging from ornate initial letters to human face and decoration objects in the painting. Below are the 35 categories:

Number of occurences of each query in DocExplorer dataset
The exhaustive annotation of the 1500 images of the collection has been performed using the DocExplore software and has yielded 1447 possible queries. The number of occurrences in each graphical object (or group) varies from 2 to more than 100. Each query differs from its corresponding occurrences in the same group by color and slight shape differences, varying size, distortion during scanning, and degradations due to aging. Queries are small and their areas can be as low as 220 (20×11) pixels. Below is an illustration of possible variability within some categories:

Variability of queries in DocExplorer dataset
Pattern spotting tasks: Each occurrence in each group is used as a query and the remaining in the same group are kept as good retrieval results.
1) Image retrieval task
The aim of the image retrieval task is to retrieve as many relevant images as possible for a given query. An image is considered to be relevant if it contains at least one occurrence of the object of interest (query) regardless of its position in the retrieved image. To evaluate the image retrieval performance, a list of non-repeated images ranked by the level of confidence containing the object query must be returned by the system. The mean Average Precision (mAP) is chosen for this evaluation as this is a widely used evaluation metric for image retrieval. The average precision is the area below the precision/recall curve calculated for each query. The precision is defined as the ratio of the retrieved positive images to the total number of retrieved images. The recall is defined as the ratio of the number of retrieved positive images to the total number of positive images in the corpus. Note that if the returned image does not contain any correct occurrence but only junk object, this image will be considered as junk image and the evaluation system will ignore this image in the list.
2) Pattern localization task
Different from the image retrieval task, whose objective is just to retrieve the relevant images, the pattern localization task takes another step further by checking if the returned objects overlap with the ground truth object or not. This is to say, it looks for the precise location of the object within the image. This time, the system, instead of returning a list of non-repeated images, will return a list of objects containing both the image name and the exact location of the bounding box. In order to assess the ability of the system to locate the image regions that contain the object, the Intersection over Union (IoU) criterion is used. The IoU indicates the ratio of the overlapping (intersection) area and the union-ed area between the bounding box of the ground truth object and that of the returned object:
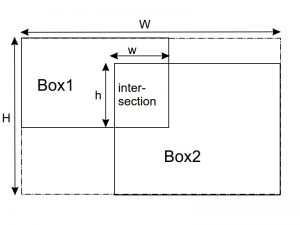
Illustration of intersection over union (IoU).
We fix the IoU ≥ 0.5 to consider that a returned bounding box is a good retrieval and the precision/recall is calculated accordingly. Finally, a single measure of the performance using the mean average precision is calculated.
Note: Initially, 1464 objects have been annotated in the dataset, and not 1447. However, among these 1464 objects, a small part (17 objects) is too different from the other annotated objects in the same category, i.e. the variability is too high with respect to the criteria. Thus, we do not use them as queries, and consider them as junk: during the evaluation process, if the spotting system returns those objects, they will be considered as not present in the ranking list. The image that contains at least one junk and does not contain any good objects will also be considered as junk image. This allows us not to penalize systems that neither retrieve nor miss this kind of object.